













 AI智能应用开发
AI智能应用开发 AI大模型开发(Python)
AI大模型开发(Python) AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+机器人开发
AI嵌入式+机器人开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作与直播运营
AI视频创作与直播运营 微短剧拍摄剪辑
微短剧拍摄剪辑 C/C++
C/C++ 狂野架构师
狂野架构师


Python文本数据分析:NLTK与jieba概述
更新时间:2022年11月08日10时11分 来源:传智教育 浏览次数:

NLTK全称为Natural Language Toolkit,它是一套基于Python的自然语言处理工具包,可以方便地完成自然语言处理的任务,包括分词、词性标注、命名实体识别(NER)及句法分析等。
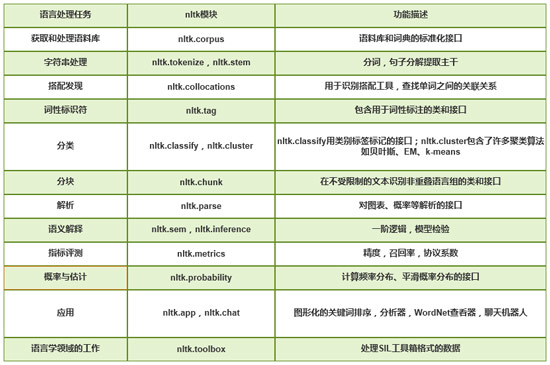
NLTK是一个免费的、开源的、社区驱动的项目,它为超过50个语料库和词汇资源(如WordNet)提供了易于使用的接口,以及一套用于分类、标记化、词干化、解析和语义推理的文本处理库。接下来,通过一张表来列举NLTK中用于语言处理任务的一些常用模块,具体如表8-1所示。
表8-1 NLTK中的常用模块
GitHub上有一段描述Jieba的句子:
“jieba”(Chinese for “to stutter”)Chinese text segmentation:built to be the best Python Chinese word segmentation module.
翻译:“Jieba”中文分词:最好的Python中文分词组件。
由此可见,jieba最适合做中文分词,这离不开它拥有的一些特点:
(1)支持三种分词模式:
◆精确模式:视图将句子最精确地切开,适合文本分析。
◆全模式:把句子中所有的可以成词的词语都扫描出来,速度非常快,但是不能解决歧义。
◆搜索引擎模式:在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
(2)支持繁体分词。
(3)支持自定义词典。
(4)MIT授权协议。
jieba库中主要的功能包括分词、添加自定义词典、关键词提取、词性标注、并行分词等,大家可以参考https://github.com/fxsjy/jieba网址进行全面学习。后期在使用到jieba库的某些功能时,会再另行单独介绍。
最新资讯




















江苏传智播客教育科技股份有限公司 版权所有Copyright 2006-2024 All
Rights Reserved
苏ICP备16007882号营业执照增值电信业务经营许可证出版物经营许可证 苏公网安备 32132202001156号
苏公网安备 32132202001156号
免费领取黑马程序员AI通道专属星级课程资料
