













 AI智能应用开发
AI智能应用开发 AI大模型开发(Python)
AI大模型开发(Python) AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+机器人开发
AI嵌入式+机器人开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作与直播运营
AI视频创作与直播运营 微短剧拍摄剪辑
微短剧拍摄剪辑 C/C++
C/C++ 狂野架构师
狂野架构师


网络爬虫是怎样抓取网页的?【爬虫流程】
更新时间:2023年05月09日14时19分 来源:传智教育 浏览次数:

通用网络爬虫和聚焦网络爬虫尽管工作原理有一些差别,但它们抓取网页的流程是类似的。图1展示了网络爬虫抓取网页的详细流程,可以帮助大家更好地理解网络爬虫抓取网页的详细过程。
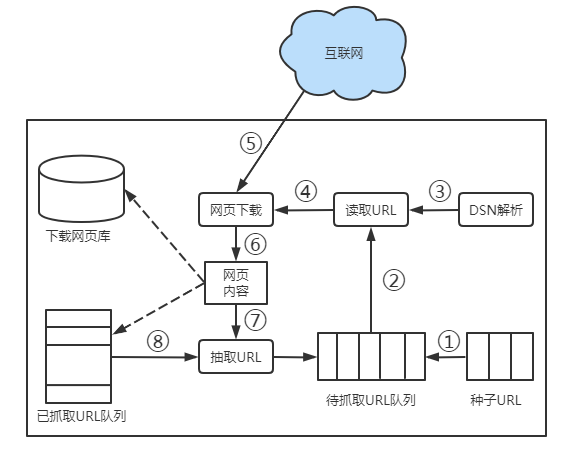
图1 网络爬虫抓取网页详细流程
关于图1中抓取网页流程的详细介绍如下。
(1)选择一些网页,将这些网页的链接作为种子URL放入待抓取URL队列中。
(2)从待抓取URL队列中依次读取URL。
(3)通过DNS解析URL,把URL地址转换为网站服务器所对应的IP地址。
(4)将IP地址和网页相对路径名称交给网页下载器,网页下载器负责网页内容的下载。
(5)网页下载器将相应网页的内容下载到本地。
(6)将下载到本地的网页存储到页面库中,等待建立索引等后续处理;与此同时,将下载过网页的URL放入已抓取URL队列中。这个队列记载了网络爬虫已经下载过的网页URL,以避免网页重复抓取。
(7)从刚下载的网页中抽取出所包含的URL信息。
(8)在已抓取URL队列中检查抽取的URL是否被下载过。如果它还未被下载过,则将这个URL放入待抓取URL队列中。
如此重复步骤(2)~步骤(8),直到待抓取URL队列为空时停止抓取。
最新资讯
0
分享到:




















江苏传智播客教育科技股份有限公司 版权所有Copyright 2006-2024 All
Rights Reserved
苏ICP备16007882号营业执照增值电信业务经营许可证出版物经营许可证 苏公网安备 32132202001156号
苏公网安备 32132202001156号
免费领取黑马程序员AI通道专属星级课程资料
