













 AI智能应用开发
AI智能应用开发 AI大模型开发(Python)
AI大模型开发(Python) AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+机器人开发
AI嵌入式+机器人开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作与直播运营
AI视频创作与直播运营 微短剧拍摄剪辑
微短剧拍摄剪辑 C/C++
C/C++ 狂野架构师
狂野架构师


SparkStreaming连接Kafka两种方式
更新时间:2021年12月16日18时18分 来源:传智教育 浏览次数:
Spark Streaming支持从多种数据源获取数据,其中就包括 Kafka,要想从 数据源获取数据,首先要建立两者之间的连接,本节来介绍两种连接Kafka的方式。
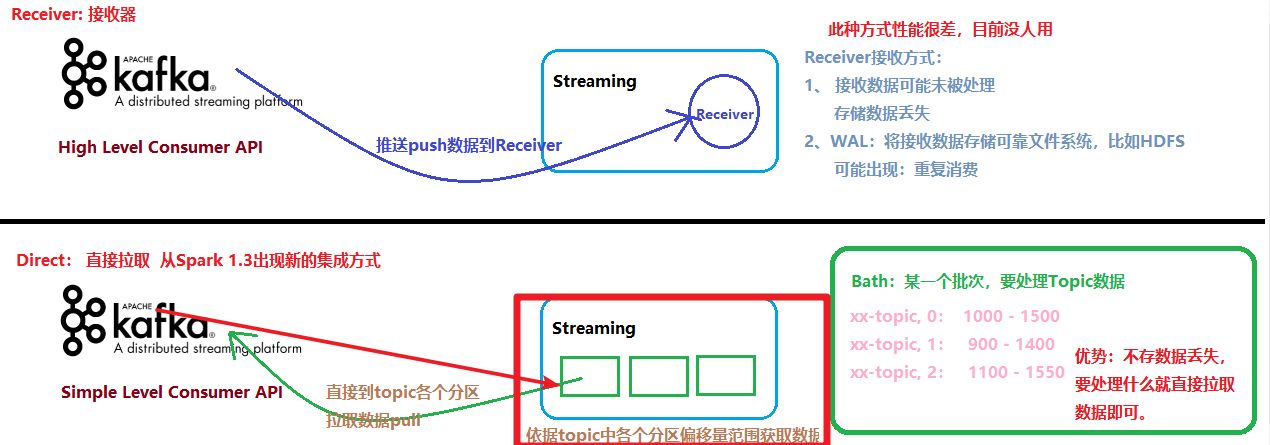
1.Receiver based Approach:
(1)KafkaUtils.createDstream基于接收器方式,消费Kafka数据已淘汰企业中不再使用;
(2)Receiver作为常驻的Task运行在Executor等待数据,但是一个Receiver效率低,需要开启多个,再手动合并数据(union),再进行处理,很麻烦;
(3)Receiver那台机器挂了,可能会丢失数据,所以需要开启WAL(预写日志)保证数据安全,那么效率又会降低;
(4)Receiver方式是通过zookeeper来连接kafka队列,调用Kafka高阶API,offset存储在zookeeper,由Receiver维护
(5)Spark在消费的时候为了保证数据不丢也会在Checkpoint中存一份offset,可能会出现数据不一致;
2.· Direct Approach (No Receivers):
(1)KafkaUtils.createDirectStream直连方式,Streaming中每批次的每个job直接调用Simple Consumer API获取对应Topic数据,此种方式使用最多,面试时被问的最多;
(2)Direct方式是直接连接kafka分区来获取数据,从每个分区直接读取数据大大提高并行能力
(3)Direct方式调用Kafka低阶API(底层APl),offset自己存储和维护,默认由Spark维护在checkpoint中,消除了与zk不一致的情况
(4)当然也可以自己手动维护,把offset存在MySQL/Redis中;
两种API
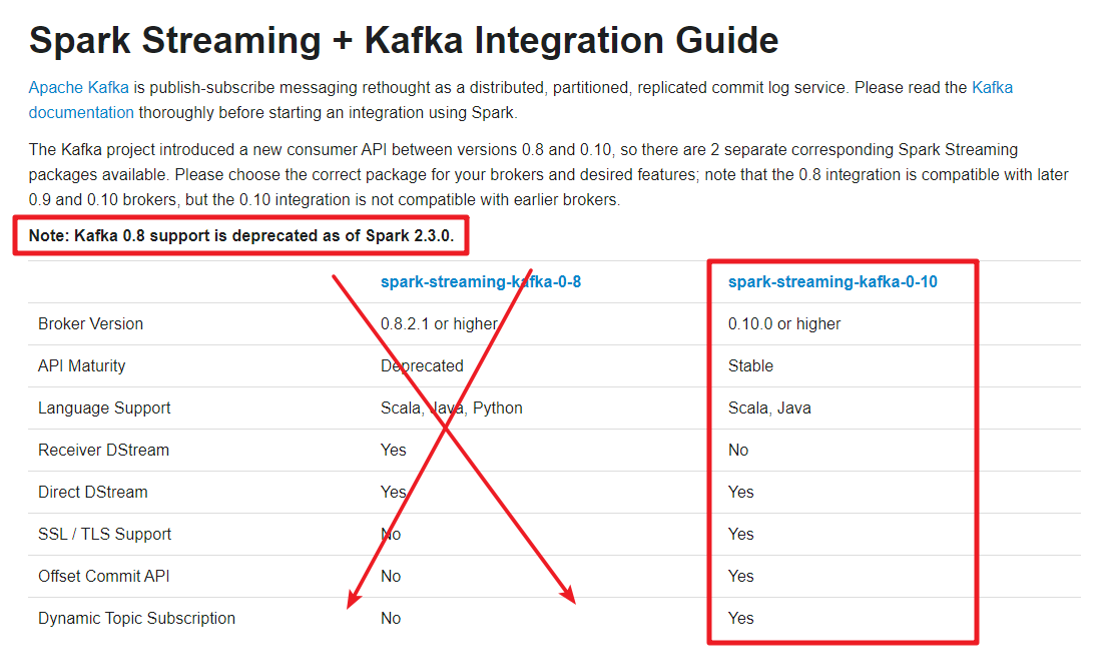
Spark Streaming与Kafka集成,有两套API,原因在于Kafka Consumer API有两套,文档:
http://spatkapathe.org/docs/2.4.5/streaming-kafka-integration.html
http://spark apache.org/docs/latest/streaming-kafka-integration.html
Kafka0.8.x版本-早已淘汰
底层使用老的KafkaAPI:Old Kafika Consumer API
支持Receiver(已淘达)和Direct模式:
Kafka 0.10.x版本-开发中使用
底层使用新的KafkaAPI:New Kafka Consumer API
只支持Direct模式
两个版本API

猜你喜欢:
最新资讯




















江苏传智播客教育科技股份有限公司 版权所有Copyright 2006-2024 All
Rights Reserved
苏ICP备16007882号营业执照增值电信业务经营许可证出版物经营许可证 苏公网安备 32132202001156号
苏公网安备 32132202001156号
免费领取黑马程序员AI通道专属星级课程资料
