













 AI智能应用开发
AI智能应用开发 AI大模型开发(Python)
AI大模型开发(Python) AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+机器人开发
AI嵌入式+机器人开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作与直播运营
AI视频创作与直播运营 微短剧拍摄剪辑
微短剧拍摄剪辑 C/C++
C/C++ 狂野架构师
狂野架构师


全部 Python+大数据新闻动态 Python+大数据技术文章 Python+大数据学习常见问题 技术问答
-
-

什么是pygame?怎样安装使用?
pygame是为开发2D游戏而设计的Python跨平台模块,开发人员利用pygame模块中定义的接口,可以方便快捷地实现诸如图形用户界面创建、图形和图像的绘制、用户键盘和鼠标操作的监听以及播放音频等游戏中常用的功能。 查看全文>>
Python+大数据技术文章2021-11-05 |传智教育 |pygame,pygame安装
-

python开发之游戏循环和游戏时钟
众所周知,游戏启动后一般由玩家手动关闭,但目前的程序在开启图形窗口并设做标题后退出,这是因为程序已经执行完毕。若要使游成保持运行,需要在程序中添加一个无限循环,循环代码如下: 查看全文>>
Python+大数据技术文章2021-11-05 |传智教育 |Python游戏模块,游戏循环与游戏时钟
-

中文分词模块jieba有几种模式?
随着汉语言的广泛应用,中文信息处理成了一个重要的研究课题,常见于搜索引擎:信息检索、中外文自动翻译、数据挖掘技术、自然语言处理等领域。在处理的过程中,中文分词是最基础的一环。 查看全文>>
Python+大数据技术文章2021-11-05 |传智教育 |jieba中文分词模块
-
如何实现pygame的初始化和退出操作?
pygame模块针对不同的开发需求提供了不同的子模块,例如显示模块、字体模块、混音器模块等,一些子模块在使用之前必须进行初始化,比如字体模块。为了使开发人员能够更简捷地使用pygame, pygame提供了如下两个函数。 查看全文>>
Python+大数据技术文章2021-11-05 |传智教育 |pygame的模块初始化和退出
-

Python中字典的常见操作
Python为字典提供了一些很实用的内建方法,使用这些方法可以帮助读者在工作中应对涉及字典的问题,简化开发的步骤。此外,Python还提供了一些字典的常用操作。具体如下表: 查看全文>>
Python+大数据技术文章2021-11-05 |传智教育 |Python中字典的常见操作
-

如何在MySQL数据库中写入数据?
SparkSQL不仅能够查询MySQL数据库中的数据,还可以向表中插人新的数据,实现方式的具体代码如文件4-5所示。 查看全文>>
Python+大数据技术文章2021-11-01 |传智教育 |MySQL数据库写入数据
-

什么是Spark SQL?Spark SQL简介
Spark SQL的前身是Shark,Shark最初是美国加州大学伯克利分校的实验室开发的Spark生态系统的组件之一,它运行在Spark系统之上,Shark重用了Hive的工作机制,并直接继承了Hive的各个组件,Shark将SQL语句的转换从MapReduce作业替换成了Spark作业,虽然这样提高了计算效率,但由于Shark过于依赖Hive,因此在版本迭代时很难添加新的优化策略... 查看全文>>
Python+大数据技术文章2021-10-29 |传智教育 |什么是Spark SQL
-
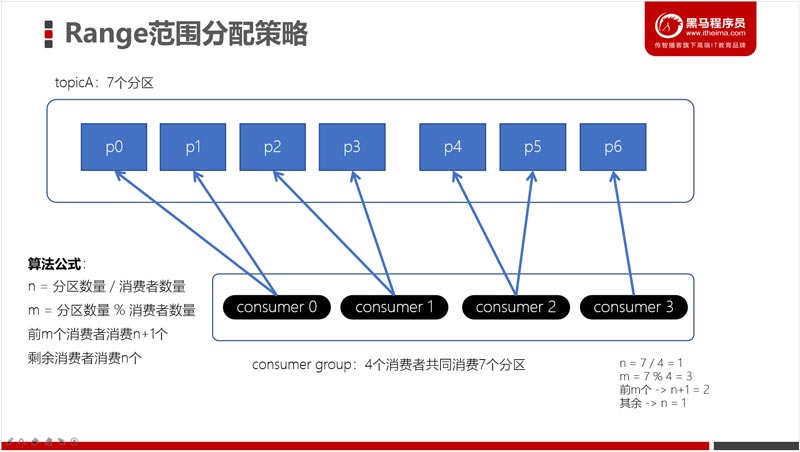
消费者分区分配策略:Stricky、Range、RoundRobin
Range范围分配策略是Kafka默认的分配策略,它可以确保每个消费者消费的分区数量是均衡的。注意:Rangle范围分配策略是针对每个Topic的。 查看全文>>
Python+大数据技术文章2021-10-29 |传智教育 |消费者分区分配策略,Stricky,Range,RoundRobin
-

















江苏传智播客教育科技股份有限公司 版权所有Copyright 2006-2024 All
Rights Reserved
苏ICP备16007882号营业执照增值电信业务经营许可证出版物经营许可证 苏公网安备 32132202001156号
苏公网安备 32132202001156号
免费领取黑马程序员AI通道专属星级课程资料
