













 AI智能应用开发
AI智能应用开发 AI大模型开发(Python)
AI大模型开发(Python) AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+机器人开发
AI嵌入式+机器人开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作与直播运营
AI视频创作与直播运营 微短剧拍摄剪辑
微短剧拍摄剪辑 C/C++
C/C++ 狂野架构师
狂野架构师


全部 Python+大数据新闻动态 Python+大数据技术文章 Python+大数据学习常见问题 技术问答
-
-
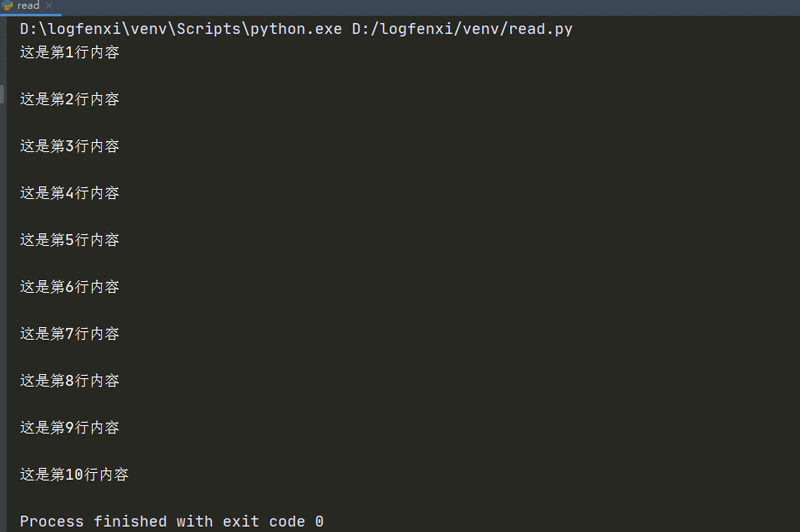
python如何一行一行读取文件内容?
Python中readline()每次读取文件中的一行,需要使用永真表达式循环读取文件。但当文件指针移动到文件的末尾时,依然使用readline()读取文件将出现错误。因此程序中需要添加1个判断语句,判断文件指针是否移动到文件的尾部,并且通过该语句中断循环。下面这段代码演示了readline()的使用。 查看全文>>
Python+大数据技术文章2020-11-11 |传智播客 |python一行一行读取
-
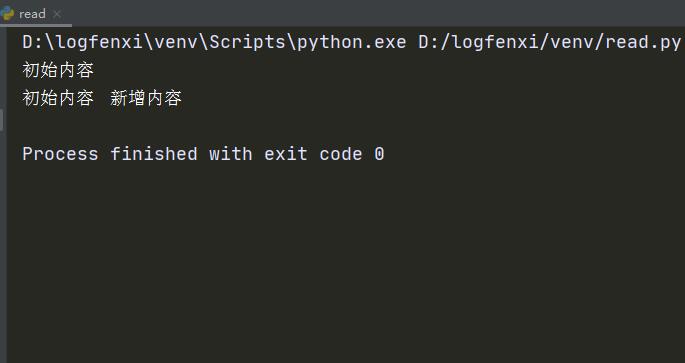
python读写文件操作详细介绍【传智播客】
Python文件的打开或创建可以使用函数open()。该函数可以指定处理模式,设置打开的文件为只读、只写或可读写状态。open()的声明如下所示。 查看全文>>
Python+大数据技术文章2020-11-11 |传智播客 |python读写文件操作
-
如何将Python数组转为Json格式数据并存储?
在Python中将数组转为Json数据存储时需要用到将json模块中的json.dumps()或者json.dump()方法。 查看全文>>
Python+大数据技术文章2020-10-09 |传智播客 |将Python数组转为Json格式数据并存储
-

JSON和XML的区别:json和xml的优缺点对比
JSON和XML都是文本格式语言,都被经常用于数据交换和网络传输,那么它们有什么区别呢?下面我们对这两种语言进行比较。 查看全文>>
Python+大数据技术文章2020-10-07 |传智播客 |JSON和XML的区别
-

Python正则表达式re模块常用函数有哪些?
Python中的re模块是正则表达式模块,该模块提供了文本匹配查找、文本替换、文本分割等功能。re模块中常用的函数及方法如表1所示。 查看全文>>
Python+大数据技术文章2020-09-30 |传智播客 |Python正则表达式,re模块常用函数
-

Python中如何实现多线程?【Python面试题】
Python中可以使用threading模块以及threading.Thread子类实现多线程。 查看全文>>
Python+大数据技术文章2020-09-29 |传智播客 |Python中如何实现多线程
-

什么是分布式爬虫?分布式爬虫实现方法
分布式爬虫就是多台计算机上都安装爬虫程序,共享队列,去重,让多个爬虫不爬取其他爬虫爬取过的内容,从而实现实现联合采集。 查看全文>>
Python+大数据技术文章2020-09-29 |传智播客 |什么是分布式爬虫,分布式爬虫实现方法
-

常见的Python反爬方式有哪些?【Python面试题】
通过headers中的User-Agent字段来反爬。最好的反爬方式是使用User-Agent池,我们可以收集一些User-Agent,或者随机生成User-Agent。通过添加referer字段或者是其他字段来反爬。通过cookie来反爬。若目标网站无需登录,则每次请求带上上次返回的cookie,比如requests模块的session;若目标网站需要登录,则准备多个账号,通过一个程序获取账号对应的cookie,组成cookie池,其他程序使用这些cookie。 查看全文>>
Python+大数据技术文章2020-09-29 |传智播客 |常见的Python反爬方式有哪些
-

















江苏传智播客教育科技股份有限公司 版权所有Copyright 2006-2024 All
Rights Reserved
苏ICP备16007882号营业执照增值电信业务经营许可证出版物经营许可证 苏公网安备 32132202001156号
苏公网安备 32132202001156号
免费领取黑马程序员AI通道专属星级课程资料
