













 AI智能应用开发
AI智能应用开发 AI大模型开发(Python)
AI大模型开发(Python) AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+机器人开发
AI嵌入式+机器人开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作与直播运营
AI视频创作与直播运营 微短剧拍摄剪辑
微短剧拍摄剪辑 C/C++
C/C++ 狂野架构师
狂野架构师


全部 Python+大数据新闻动态 Python+大数据技术文章 Python+大数据学习常见问题 技术问答
-
-
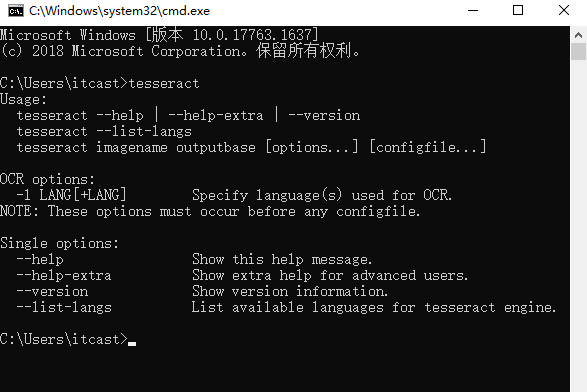
tesseract下载安装与环境变量配置教程
Tesseract是一个开源的OCR库,是目前公认的最优秀、最精确的开源OCR系统,具有精准度高、灵活性高等特点。它不仅可以通过训练识别出任何字体(只要字体的风格保持不变即可),而且可以识别出任何Unicode字符。 查看全文>>
Python+大数据技术文章2021-06-25 |传智教育 |Tesseract下载安装教程,环境变量配置
-

urllib和requests哪个好用?
requests是基于Python开发的HTTP库,与urllib标准库相比,它不仅使用方便,而且能节约大量的工作。实际上,requests是在urllib的基础上进行了高度的封装,它不仅继承了urllib的所有特性,而且还支持一些其他的特性,例如,使用Cookie保持会话、自动确定响应内容的编码等,可以轻而易举地完成浏览器的任何操作。 查看全文>>
Python+大数据技术文章2021-06-23 |传智教育 |urllib和requests哪个好用
-
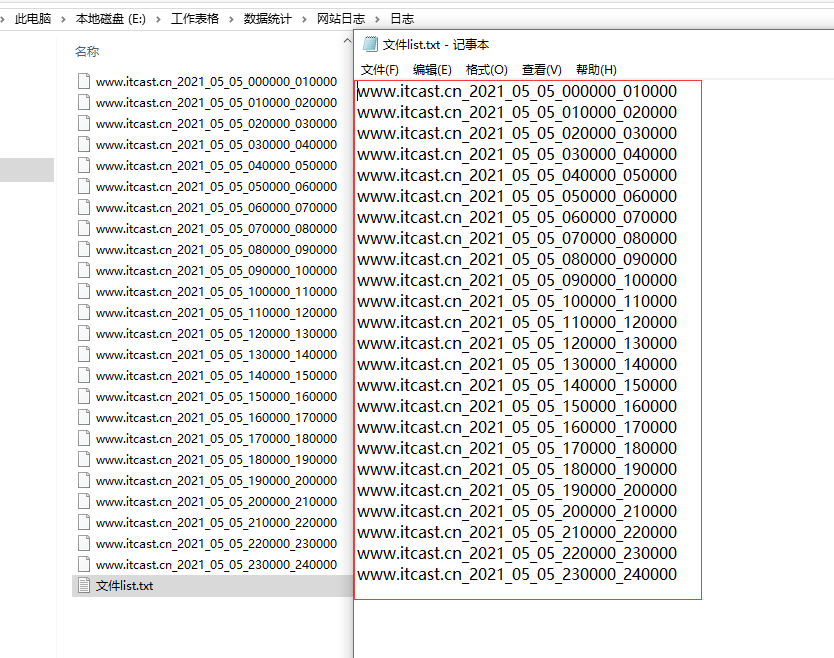
python获取当前文件夹下所有文件名【附代码】
有些时候我们需要获取某个文件夹下的所有文件的名称,手工操作效率低下而且容易出错,使用Python如何实现这个功能呢? 查看全文>>
Python+大数据技术文章2021-06-22 |传智教育 |python获取当前文件夹下所有文件名
-
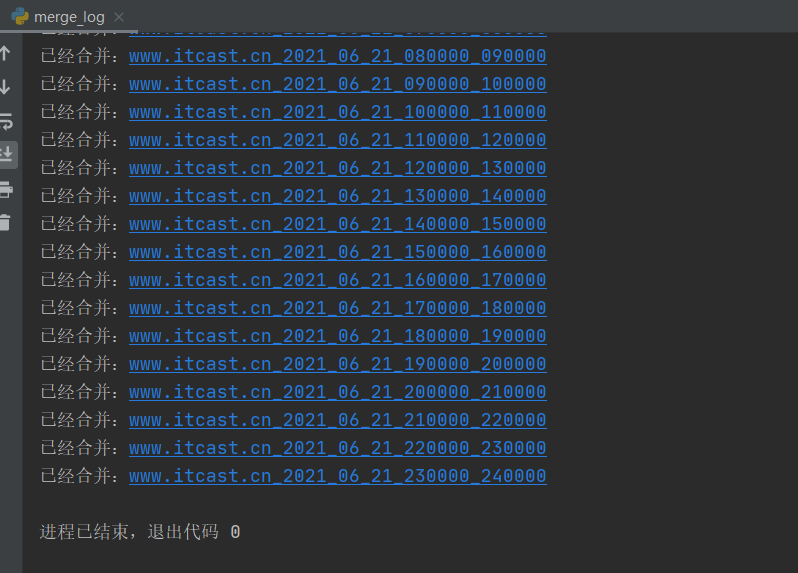
python合并多个txt文件的方法【附可运行代码】
很多时候我们需要将很多同类型的文件合并成一个文件,手工操作效率很低,下面我们通过一个案例来介绍使用Python合并文件夹内容的方法。 查看全文>>
Python+大数据技术文章2021-06-22 |传智教育 |python合并,python合并文件
-

JSON是什么意思?有什么用?
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,可使人们很容易地进行阅读和编写,同时也方便了机器进行解析和生成。JSON适用于进行数据交互的场景,如网站前台与后台之间的数据交互。 查看全文>>
Python+大数据技术文章2021-06-21 |传智教育 |JSON是什么意思
-
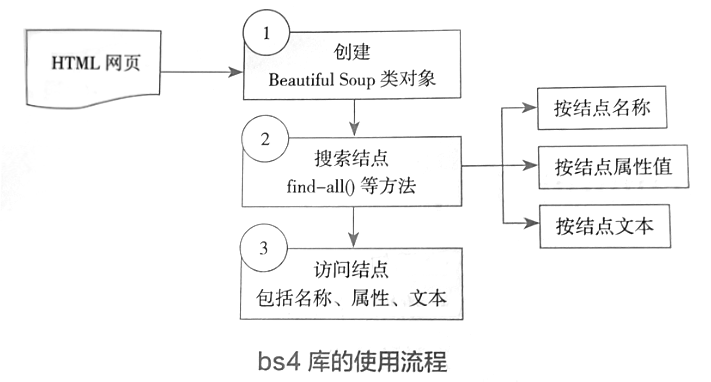
BeautifulSoup库的功能介绍【BeautifulSoup教程】
使用lxml库时需要编写和测试XPath语句,显然降低了开发效率。除了lxml库之外,还可以使用Beautiful Soup来提取HTML/XML数据。虽然这两个库的功能相似,但是Beautiful Soup使用起来更加简洁方便,受到开发人员的推崇。 查看全文>>
Python+大数据技术文章2021-06-21 |传智教育 |BeautifulSoup库的功能
-

lxml库获取子节点的方法汇总
lxml是使用Python语言编写的库,主要用于解析和提取HTML或者XML格式的数据,它不仅功能非常丰富,而且便于使用,可以利用XPath语法快速地定位特定的元素或节点。 查看全文>>
Python+大数据技术文章2021-06-21 |传智教育 |lxml库获取子节点
-
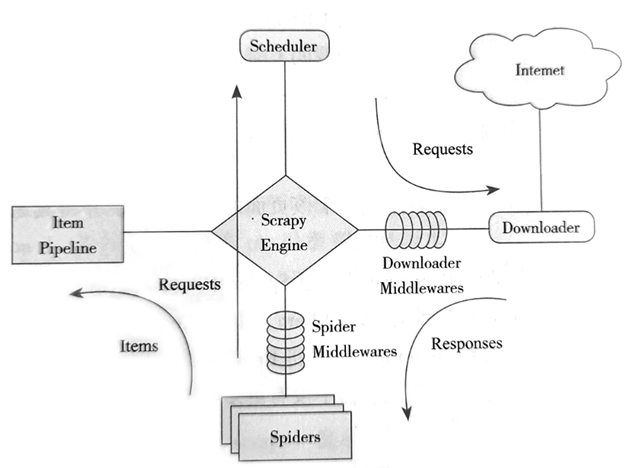
Scrapy框架结构组件有哪些?【Scrapy框架介绍】
学习Scrapy框架,从理解它的架构开始。Scrapy的这些组件通力合作,共同完成整个爬取任务。架构图中的箭头是数据的流动方向,首先从初始URL开始,Scheduler 会将其交给Downloader进行下载,下载之后会交给Spiders进行分析。Spiders分析出来的结果有两种:一种是需要进一步爬取的链接,例如之前分析的“下一页”的链接,这些会被传回Scheduler; 查看全文>>
Python+大数据技术文章2021-06-18 |传智教育 |Scrapy框架结构组件有哪些
-

















江苏传智播客教育科技股份有限公司 版权所有Copyright 2006-2024 All
Rights Reserved
苏ICP备16007882号营业执照增值电信业务经营许可证出版物经营许可证 苏公网安备 32132202001156号
苏公网安备 32132202001156号
免费领取黑马程序员AI通道专属星级课程资料
